##################
# e-Stat共通設定 #
##################
# e-StatAPIのDataBaseが格納されているURL
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
# 対象期間
cdTime = "2021000000"
######################################################
# e-StatAPIから出生率(e-StatDataID=0003411597)をGet #
######################################################
# e-StatDataID(対象DataBaseに固有のID
statsDataId = "0003411597"
# Processing Pandas data and change the column name
column_rename = {
'@tab': 'DataType',
'@area': '都道府県コード',
'@time': '対象年',
'@unit': '単位',
'$': '出生率'
}
tree = "['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']"
df = fn_get_estat_data(APP_ID, API_URL, statsDataId, cdTime, column_rename, tree)
df.head()
##########################################
# 都道府県コードを都道府県の名称に置き換え
##########################################
#Dataの構造が格納されているMetaInfoを取得
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getMetaInfo?"
params = {
"appId": APP_ID,
"statsDataId": statsDataId,
"limit": 2,
"lang": "J" # 日本語を指定
}
response = requests.get(API_URL, params=params)
data = response.json()
data
# META_INFOの中から都道府県コードと都道府県名を対比している箇所を取得
values = data['GET_META_INFO']['METADATA_INF']['CLASS_INF']['CLASS_OBJ']
#pprint.pprint(values)
for dictionary in values:
if dictionary['@id'] == 'area':
pref_list = dictionary['CLASS']
prefectures_list = {}
for pref_code in pref_list:
prefectures_list[pref_code['@code']] = pref_code['@name']
# 先ほど作成した辞書を使用して、都道府県コードに基づき、
# 都道府県名の列を追加するための関数を定義
def replace_pref_name(pref_code):
return prefectures_list.get(pref_code, None)
# 都道府県コード列を都道府県名列に置き換え
df["都道府県"] = df["都道府県コード"].apply(replace_pref_name)
df_birth_rate = df[df['DataType']=='10050']
#print(df_birth_rate)
######################################################
# e-StatAPIから婚姻率(e-StatDataID=0003411835)をGet #
######################################################
# e-StatAPIのDataBaseが格納されているURL
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData"
# e-StatDataID(対象DataBaseに固有のID)
statsDataId = "0003411835"
# 対象期間
#cdTime = "2021000000"
# Processing Pandas data and change the column name
column_rename = {
'@tab': 'DataType',
'@area': '都道府県コード',
'@time': '対象年',
'@unit': '単位',
'$': '婚姻率'
}
tree = "['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE']"
df = fn_get_estat_data(APP_ID, API_URL, statsDataId, cdTime, column_rename, tree)
#df.head()
##########################################
# 都道府県コードを都道府県の名称に置き換え
##########################################
#Dataの構造が格納されているMetaInfoを取得
API_URL = "http://api.e-stat.go.jp/rest/3.0/app/json/getMetaInfo?"
params = {
"appId": APP_ID,
"statsDataId": statsDataId,
"limit": 2,
"lang": "J" # 日本語を指定
}
response = requests.get(API_URL, params=params)
data = response.json()
data
# META_INFOの中から都道府県コードと都道府県名を対比している箇所を取得
values = data['GET_META_INFO']['METADATA_INF']['CLASS_INF']['CLASS_OBJ']
for dictionary in values:
if dictionary['@id'] == 'area':
pref_list = dictionary['CLASS']
prefectures_list = {}
for pref_code in pref_list:
prefectures_list[pref_code['@code']] = pref_code['@name']
# 先ほど作成した辞書を使用して、都道府県コードに基づき、
# 都道府県名の列を追加するための関数を定義
def replace_pref_name(pref_code):
return prefectures_list.get(pref_code, None)
# 都道府県コード列を都道府県名列に置き換え
df["都道府県"] = df["都道府県コード"].apply(replace_pref_name)
df_marriage_rate = df[df['DataType']=='10280']
#print(df_marriage_rate)
#出生率のDataを新しいDataFrame'df_data'にコピー
df_data = df_birth_rate[['都道府県', '出生率']].copy()
#婚姻率のDataをDataFrame'df_data'に入力
for index,row in df_marriage_rate.iterrows():
df_data.loc[df_data['都道府県'] == row["都道府県"], "婚姻率"] = row["婚姻率"]
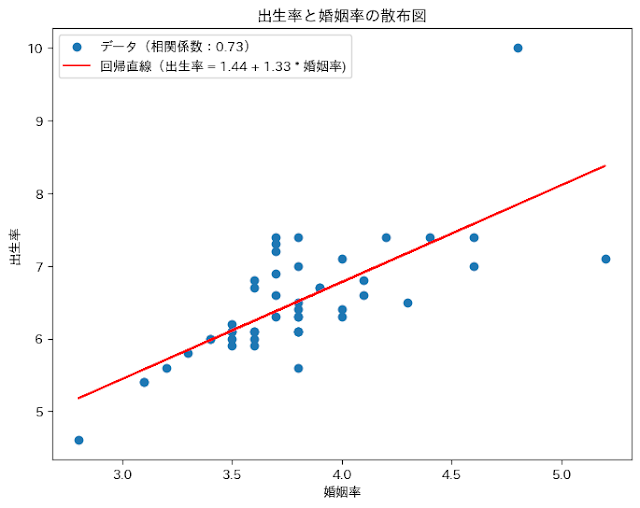
print(df_data)


.png)



コメント
コメントを投稿