HTML言語を全く知らない拙者がPythonのライブラリBeautiful Soupを使用してWebscrapingにTry。
Python講師いまにゅ先生やPythonYouTuberサプー先生のYouTubeを参考に、わたしなりに素材を見つけて、WebScrapingにチャレンジしてみました。
まず素材ですが、「ふるさとチョイス」さんのふるさと納税返礼品リストを使ってみることにしました。あまり商品数が多すぎると整理が複雑になりますし、少なすぎるとWebScrapingらしくならないので、少しマニアックなWordでSearchしてみたところ、Hit22itemというReasonableな品物を見つけました。
SearchWordは「クラリネット」です。Search resultのスクショです。
これらの商品のitem name,(商品名) price(価格=寄付金額), product city(自治体)を取得して、tableに整理します。
必要なlibraryをimportします。
!pip install beautifulsoup4
from bs4 import BeautifulSoup
import requests
from posixpath import split
import pandas as pd
次にsearch resultのWeb siteのaddressをCopy and pasteしたあと、requestでweb siteを呼び出し、HTML fileを読み込みます。
url_ec = 'https://www.furusato-tax.jp/search?q=%E3%82%AF%E3%83%A9%E3%83%AA%E3%83%8D%E3%83%83%E3%83%88&header=1&target=1&sst=B'
res = requests.get(url_ec)
soup = BeautifulSoup(res.text, 'html.parser')
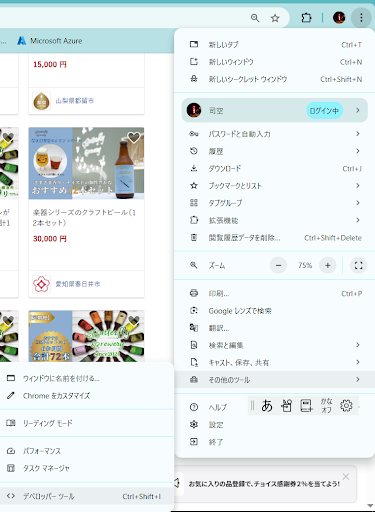
soup.find_allを使用して、HTMLFileのpとかidといったtagとclassに注目して、欲しい情報を取得します。tagやclassの確認はGoogleChromeを使用している場合は、画面左上の設定・メニューから「その他ツール-デベロッパーツール」を利用してHTMLのコードを確認します。デベロッパーツールの使い方は別途調べてみてください。
# Get item name, price, city
item_titles = soup.find_all('p', class_="card-product__title") # Beautiful soupで必要なデータを取得
item_prices = soup.find_all('p', class_="card-product__price")
item_cities = soup.find_all('a', class_="card-product__city")
このコードによりふるさとチョイスさんの画面に表示されている全てのふるさと納税の商品名、寄付額、自治体がリスト形式で取得されます。
次に、3つのリスト形式に格納されているデータをforループを回して、商品ごとに辞書形式にまとめます。
data_ec = []
for item_title, item_price, item_city in zip(item_titles, item_prices, item_cities):
datum_ec = {} # 項目名:数値or文字列を仮入力するための辞書の生成
item_title = item_title.text
start_index = item_title.find('>') + 1 # 必要な文字列の前にあるHTMLコードの文字数をカウント
end_index = item_title.rfind('<') # # 必要な文字列の後ろにあるHTMLコードの文字数をカウント
item_tile = item_title[start_index:end_index].strip() # 必要な文字列以外を削除
item_tile = item_tile.replace('\u3000', ' ') # 文字列の途中に存在する'\u'を削除
datum_ec['title'] = item_tile # 辞書datum_ecにtitle:商品名を入力
item_price = item_price.text
start_index = item_price.find('>') + 1
end_index = item_price.rfind('<')
item_price = item_price[start_index:end_index].strip()
# カンマを除去
item_price = item_price.replace(',', '')
# 整数型に変換
if item_price == '':
continue
else:
datum_ec['price'] = int(item_price)
item_city = item_city.text
start_index = item_city.find('>') + 1
end_index = item_city.rfind('<')
item_city = item_city.strip()
if item_city == '':
continue
else:
datum_ec['city'] = item_city
data_ec.append(datum_ec)
最後に、辞書形式のデータをpandasDataFrameに変換して、表形式で表示しやすくします。
df_data_ec = pd.DataFrame(data_ec)
コードをまとめて、関数化すると以下のようになります。
def func_get_data_ec():
#url_ec = 'https://www.furusato-tax.jp/search?q=%E3%82%A2%E3%83%AB%E3%83%88%E3%82%B5%E3%83%83%E3%82%AF%E3%82%B9&header=1&target=1&sst=B'
url_ec = 'https://www.furusato-tax.jp/search?q=%E3%82%AF%E3%83%A9%E3%83%AA%E3%83%8D%E3%83%83%E3%83%88&header=1&target=1&sst=B'
res = requests.get(url_ec)
soup = BeautifulSoup(res.text, 'html.parser')
# Get item name, price, city
item_titles = soup.find_all('p', class_="card-product__title") # Beautiful soupで必要なデータを取得
item_prices = soup.find_all('p', class_="card-product__price")
item_cities = soup.find_all('a', class_="card-product__city")
data_ec = []
for item_title, item_price, item_city in zip(item_titles, item_prices, item_cities):
datum_ec = {} # 項目名:数値or文字列を仮入力するための辞書の生成
item_title = item_title.text
start_index = item_title.find('>') + 1 # 必要な文字列の前にあるHTMLコードの文字数をカウント
end_index = item_title.rfind('<') # # 必要な文字列の後ろにあるHTMLコードの文字数をカウント
item_tile = item_title[start_index:end_index].strip() # 必要な文字列以外を削除
item_tile = item_tile.replace('\u3000', ' ') # 文字列の途中に存在する'\u'を削除
datum_ec['title'] = item_tile # 辞書datum_ecにtitle:商品名を入力
item_price = item_price.text
start_index = item_price.find('>') + 1
end_index = item_price.rfind('<')
item_price = item_price[start_index:end_index].strip()
# カンマを除去
item_price = item_price.replace(',', '')
# 整数型に変換
if item_price == '':
continue
else:
datum_ec['price'] = int(item_price)
item_city = item_city.text
start_index = item_city.find('>') + 1
end_index = item_city.rfind('<')
item_city = item_city.strip()
if item_city == '':
continue
else:
datum_ec['city'] = item_city
data_ec.append(datum_ec)
df_data_ec = pd.DataFrame(data_ec)
return df_data_ec
df_data_ec = func_get_data_ec()
print(df_data_ec)
出力は以下のようになります。
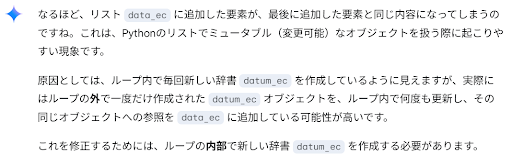
ここで豆知識。forループの中にあった辞書変数の初期化datum_ec={}をforループの外に出してしまうと、処理結果21行はすべて同じデータ(21番目のデータ)になってしまいます。(最初、このコードを書いて、エラーは出ないのにうまく処理できず悩みました)
def func_get_data_ec():
#url_ec = 'https://www.furusato-tax.jp/search?q=%E3%82%A2%E3%83%AB%E3%83%88%E3%82%B5%E3%83%83%E3%82%AF%E3%82%B9&header=1&target=1&sst=B'
url_ec = 'https://www.furusato-tax.jp/search?q=%E3%82%AF%E3%83%A9%E3%83%AA%E3%83%8D%E3%83%83%E3%83%88&header=1&target=1&sst=B'
res = requests.get(url_ec)
soup = BeautifulSoup(res.text, 'html.parser')
# Get item name, price, city
item_titles = soup.find_all('p', class_="card-product__title") # Beautiful soupで必要なデータを取得
item_prices = soup.find_all('p', class_="card-product__price")
item_cities = soup.find_all('a', class_="card-product__city")
data_ec = []; datum_ec = {} # 項目名:数値or文字列を仮入力するための辞書の生成
for item_title, item_price, item_city in zip(item_titles, item_prices, item_cities):
item_title = item_title.text
start_index = item_title.find('>') + 1 # 必要な文字列の前にあるHTMLコードの文字数をカウント
end_index = item_title.rfind('<') # # 必要な文字列の後ろにあるHTMLコードの文字数をカウント
item_tile = item_title[start_index:end_index].strip() # 必要な文字列以外を削除
item_tile = item_tile.replace('\u3000', ' ') # 文字列の途中に存在する'\u'を削除
datum_ec['title'] = item_tile # 辞書datum_ecにtitle:商品名を入力
item_price = item_price.text
start_index = item_price.find('>') + 1
end_index = item_price.rfind('<')
item_price = item_price[start_index:end_index].strip()
# カンマを除去
item_price = item_price.replace(',', '')
# 整数型に変換
if item_price == '':
continue
else:
datum_ec['price'] = int(item_price)
item_city = item_city.text
start_index = item_city.find('>') + 1
end_index = item_city.rfind('<')
item_city = item_city.strip()
if item_city == '':
continue
else:
datum_ec['city'] = item_city
data_ec.append(datum_ec)
df_data_ec = pd.DataFrame(data_ec)
return df_data_ec
df_data_ec = func_get_data_ec()
print(df_data_ec)

Gemini先生に聞いてみたところ、このような回答をいただきました。
ご参考までに。。。






コメント
コメントを投稿