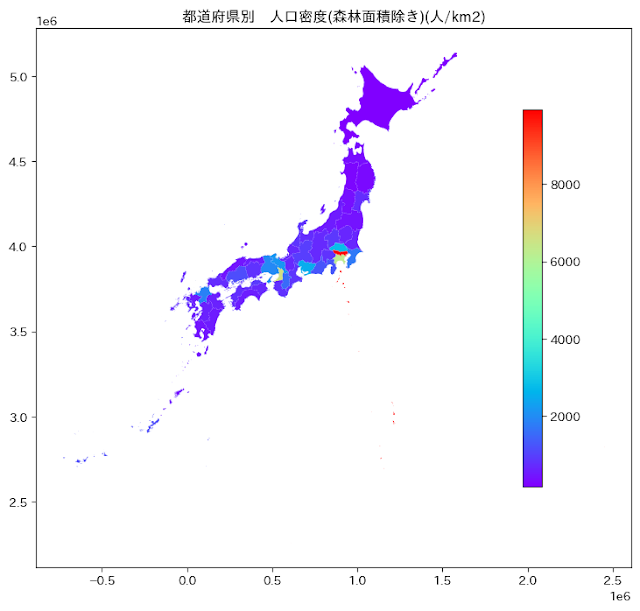
都道府県別の男女人口比率、外国人人口を図化 総務省統計局データをPythonで加工 e-Stat with Python(3)
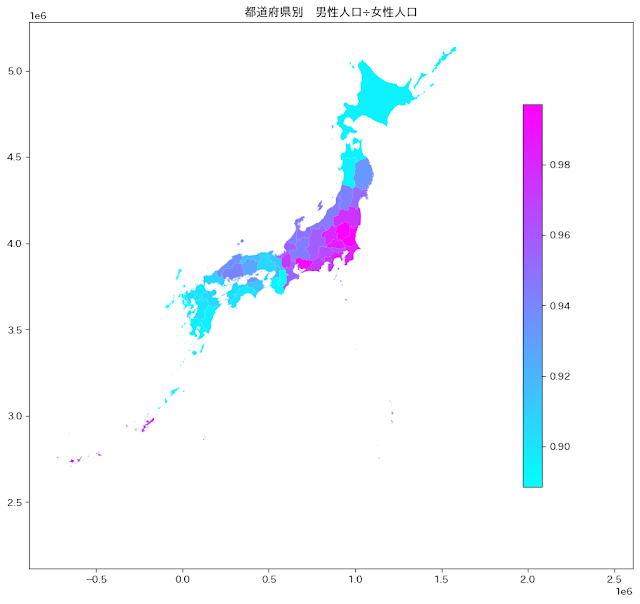
都道府県別に男女比率について整理・図化してみました。 まず最初に感じたことは「男性人口÷女性人口<1.0」であるという点です。昭和40年代生まれのわたし時代の教育では出生についていえば、「男の子>女の子」だったと記憶しているのですが、人口で整理すると、どの都道府県においても「男性<女性」であるということを知りました。平均寿命の関係があるのかなぁと想像しました。 どちらかというと大都市圏では、「男性人口≒女性人口」に近づくような傾向が見えますが、沖縄県はまあまあ男性人口と女性人口は近いような気がします。 北海道や青森、秋田、和歌山、高知、長崎、鹿児島などは男性人口≦女性人口×0.9で、年齢を忘れるとすれば、カップルを作るとすると男性が売り手市場になっているようです。分析ができていませんが、もしかすると平均寿命が男性に比べて、女性の方が高いのかもしれません。これは確認してみる必要がありそうです。 ちなみに一番「女性人口=男性人口」なのは、地図の色彩だけから見ると、福島県か愛知県? 次に外国人と思われる人口を図化してみます。数値的には、総人口-日本人人口で求めた数値を使っています。単位は千人なので、東京都だと500千人すなわち50万人の外国人がいるという計算です。こちらもやはり大都市圏が多くなる傾向を示しています。それはそうですよね。大都市圏の方が外国人のニーズも高いし、そもそも人口そのものも多いので、外国人も多くなりますよね。 ちなみに今回は人口一人当たりの数値はあまり意味がなさそうなので、図化しません。 今回はコードの掲載はなしにします。